一文了解UniProt數(shù)據(jù)庫使用技巧
UniProt數(shù)據(jù)庫全稱Universal Protein���,是由歐洲生物信息研究所(EMBL-EBI)��、瑞士蘇黎世大學的Swiss Institute of Bioinformatics(SIB)和美國國家生物技術信息中心(NCBI)三家機構合作維護的知識庫��,旨在整合��、注釋和提供全面的蛋白質序列及相關功能信息���。
該數(shù)據(jù)庫由三個主要部分組成
UniProtKB:是UniProt的核心組成部分��,分為Reviewed(Swiss-Prot)和Unreviewed(TrEMBL)。Reviewed包含專家手動注釋的高質量蛋白質數(shù)據(jù)�,包括蛋白質的功能描述、域結構��、變異信息�、文獻引用等詳細資料;TrEMBL則收集自國際核酸序列數(shù)據(jù)庫(GenBank/DDBJ/EMBL)���,包含了自動注釋的蛋白質序列數(shù)據(jù)���,主要用于那些未經(jīng)過人工審核的序列信息。

Proteomes:用于集中展示特定物種的完整蛋白質組信息���。聚焦于那些已經(jīng)完成了全基因組測序的物種�����,通過將基因組預測出的所有蛋白質編碼基因的產(chǎn)物進行編目和注解��,形成了全面的物種蛋白組圖譜���。

UniRef:是一個聚類數(shù)據(jù)庫�����,通過算法將相似的蛋白質序列歸類在一起�����,生成代表性的序列集合�����,提高數(shù)據(jù)檢索效率�����。細分為UniRef100��、UniRef90和UniRef50三種不同層次的聚類標準�����,分別對應于97%���、90%和50%的序列一致性閾值�。

UniParc:這個數(shù)據(jù)庫匯集了來自多個來源的全部蛋白質序列�,包括但不限于UniProtKB、PIR����、PRF��、NCBI RefSeq等�,它作為一個綜合存儲庫,確保每個序列只被收錄一次���,即便同一序列出現(xiàn)在多個來源中����,也只保留一份����,有效防止重復��。

舉例說明
我們今天以一個具體的基因為例子���,來演示這個數(shù)據(jù)庫的使用方法,以人源的IL-6為例���。
關鍵詞搜索:直接在首頁搜索框中輸入蛋白質名稱����、ID����、物種名、功能描述等關鍵詞進行快速檢索��。
高級搜索:點擊“Advanced”鏈接進入高級搜索頁面�����,這里可以通過構建復雜的邏輯語句(AND�����、OR、NOT)和使用特定字段(如gene��、protein name�����、organism等)進行精準查詢�����。
1
首先打開官網(wǎng)主頁:www.uniprot.org/�����,搜索欄輸入IL-6���,點擊Search或鍵盤回車���,然后左側欄選擇Human

Entry:Uniprot給每個蛋白質賦予的ID(由此進入查看具體信息)
Entry name:蛋白ID的簡要名字
Protein names:蛋白質的名字
Gene names:編碼這個蛋白的Gene名字
Organism:蛋白質的種屬來源
Length:氨基酸長度
2
找到你想要的蛋白�����,點擊進入�,到達詳情頁面����,左側欄為目錄��,點擊即可查看��,包含豐富的信息板塊�,如蛋白功能、亞細胞定位��、序列特征�����、蛋白表達與互作�����、文獻引用��、相似性蛋白��、結構域預測等����。

Function:有關蛋白質的功能信息��。
Names & Taxonomy:有關蛋白質和基因名稱和同義詞以及源生物的信息�。
Subcellular location:有關成熟蛋白質在細胞中位置的信息�。
Disease & variants/ Phenotypes & Variants:在人類條目中,有關與蛋白質相關的疾病的信息��。在非人類條目中����,有關與蛋白質相關的表型的信息。在所有情況下����,都描述了變異氨基酸的作用。
Expression:關于基因在多細胞生物的細胞或組織中mRNA或蛋白質水平的表達的信息��。
PTM/Processing:描述翻譯后修飾 (post-translational modifications����,PTM) 和/或蛋白加工等信息。
Interaction:關于蛋白質的四級結構以及與其他蛋白質或蛋白質復合物相互作用的信息�����。
Structure:關于蛋白質的三級結構的信息�����。如果沒有完整的實驗確定的結構��,在許多情況下�,將顯示 AlphaFold 預測。
Family & Domains:關于與其他蛋白質的序列相似性以及蛋白質中存在的結構域的信息�。
Sequence:默認情況下顯示規(guī)范蛋白質序列,并根據(jù)要求顯示條目中描述的所有亞型�����。還包括與序列相關的信息��,包括長度和分子量���。
Similar proteins:提供指向 UniProt 引用集群 (UniRef) 的鏈接���。
Uniprot常用功能:
BLAST,全稱Basic Local Alignment Search Tool�,是一種用于比較核酸或蛋白質序列與大型數(shù)據(jù)庫中存儲的所有序列的軟件工具包。UniProt提供的Blast工具專門針對其收錄的蛋白質序列進行優(yōu)化��,使用戶能夠搜索相似序列、蛋白功能預測��、物種進化分析��、結構建模����。
具體步驟:
1
以人類的IL-6為例,復制粘貼或輸入剛剛選擇的IL-6的Entry標識符�,會自動跳出相應的序列信息,或直接粘貼已有的序列��。

2
選擇目標數(shù)據(jù)庫�。默認情況下,搜索所有參考蛋白質組 + UniProtKB/Swiss-Prot��,但您可以選擇僅針對 UniProtKB/Swiss-Prot 中已審閱的序列運行�����。
3
限制物種選項讓你精準定位搜索范圍����,只需輸入特定代碼,例如��,輸入“9606”,搜索便只針對人類蛋白質���;若想涵蓋整個哺乳動物界,則使用“哺乳動物 [40674]”����。也可以選擇自動完成功能,輕松完成����,確保你的查詢更貼合研究需求。
4
點擊RUN blast����,等待結果。

Align��,用于兩個或多個序列的信息比對��,以識別相似區(qū)域���,這些區(qū)域可能是序列之間功能���、結構或進化關系的結果�����。
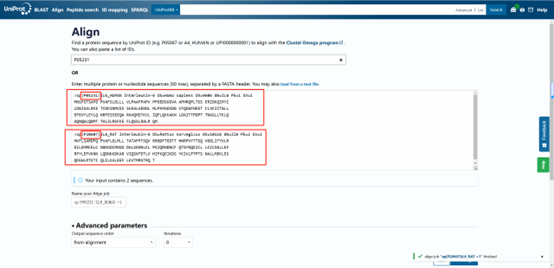
具體步驟:
1
將準備好的兩段(或兩段以上)序列輸入進去�����,或輸入Uniprot的Entry標識符����,會自動識別序列��。
2
點擊RUN Align�����,等待結果
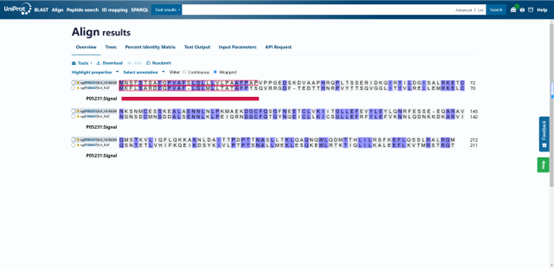
“Tree”部分通過系統(tǒng)發(fā)育樹來表示序列之間的進化關系�����。
Search with list map IDs:“檢索/ID 映射”工具���,您可以在其中提交標識符列表以檢索相應的 UniProt 條目����,或將 UniProt 標識符映射到外部數(shù)據(jù)庫,UniProt條目中包含指向GenBank��、PubMed���、KEGG����、GO等外部資源的鏈接�,方便獲取更多相關信息���。
Search peptides:多肽搜索”工具����,允許您提交至少 3 個殘基的短肽序列��,并找到與查詢序列完全匹配的所有 UniProtKB 序列
AntibodySystem
AntibodySystem Laboratories SAS于2019年創(chuàng)立于法國斯特拉斯堡,專注于生命科學研究領域蛋白及抗體試劑研發(fā)生產(chǎn)�����。致力于為全球生命科學基礎研究者提供高質量的蛋白���,抗體產(chǎn)品��,產(chǎn)品類別囊括傳統(tǒng)多抗�,經(jīng)典內參抗體,標簽抗體����,高活性蛋白,invivo功能性抗體��,低背景流式抗體�,高特異性納米抗體,特色小分子抗體���,高質量磷酸化抗體���,DNA/RNA抗體,PEG抗體等十余個系列;目前AntibodySystem旗下產(chǎn)品線涵蓋500種病毒與超級細菌,寄生蟲��,腫瘤�,老年癡呆,帕金森���,變態(tài)與過敏反應��,免疫抑制與免疫激活等多個領域�。
佰樂博生物
武漢佰樂博生物(Biolab Reagents)由五位畢業(yè)于華中科技大學,華中農(nóng)業(yè)大學�����,武漢大學等知名高校���,且具有二十年工作經(jīng)驗的生命科學領域研究者創(chuàng)立于2021年����,憑借豐富的產(chǎn)品開發(fā)經(jīng)驗����,利用全球技術平臺���,引進和整合全球高品質的蛋白�����、抗體和試劑盒產(chǎn)品�����。目前���,佰樂博生物作為法國AntibodySystem和ProteoGenix在亞洲總代理��,提供近30,000種生命科學試劑��,核心產(chǎn)品涵蓋蛋白�、抗體和試劑盒�,旨在為科研工作者提供專業(yè)、全面��、可靠的試劑支持�����,推動生命科學研究的深入發(fā)展�。